Übersicht
MaSoCist – ein linux-ähnliches Build-System für eigene CPU-Designs als OpenSource
FPGAs erlauben ein weitgehend nur durch die vorgegebenen Chip-Resourcen eingeschränktes eigenes Prozessordesign mit Peripherie.
Da auf FPGAs oft für den Anwendungszweck spezialisierte Hardware zum Einsatz kommt, kann ein software-implementierter on-chip CPU-Kern meist einfache Konfigurationsarbeiten oder die Schnittstelle zum Nutzer — die Peripherie — abdecken. Typischerweise wird dies als ‘SoC’ — System on Chip — bezeichnet.
Die MaSoCist-Umgebung (Abkürzung für Martins System on Chip Instancing/Simulation tool
erlaubt, die CPU wie auch die benötigte Peripherie weitgehend analog zum Linux Kernel zu konfigurieren und die Software wie auch die Hardware über Gerätebeschreibungen zu definieren. Damit kann u.a. die Firmware/Software, die grundsätzlich per GNU-Toolchain gebaut wird, für viele verschiedene FPGA-Plattformen verwaltet werden.
Details
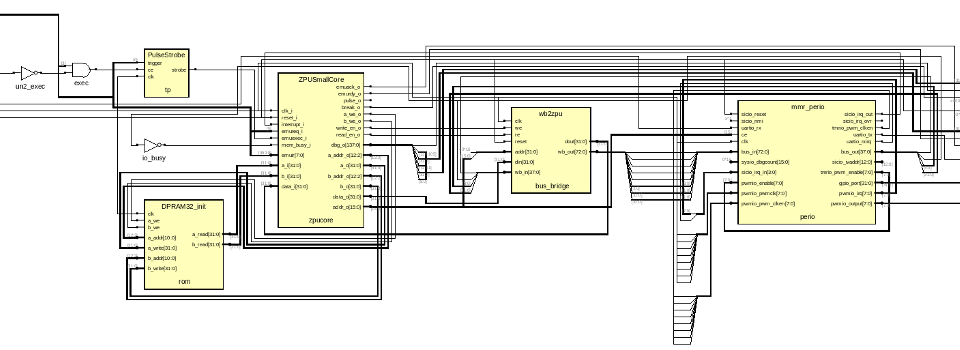
In der Nische der FPGA SoCs haben sich resourcensparende Stack-Maschinen trotz Geschwindigkeitseinbussen gegenüber komplexeren Architekturen gut etabliert, unter anderem die von Øyvind Harboe konzipierte ZPU-Architektur, die mit einem vollständigen GNU-Werkzeugkasten (gcc, gdb) daherkommt.
Sie gilt als die kompakteste 32-Bit-Architektur mit gcc-Support, da sie im Vergleich zu den proprietären Herstellerlösungen wenig Logikelemente benötigt und eine der besten Code-Dichten aufweist.
Das System ist dabei aufgebaut wie ein Linux-Kernel, nur für Hardware:
Optionen können entsprechend der Zielanwendung konfiguriert werden, werden z.B. vier UARTs benötigt, wird die zugehörige Variable CONFIG_NUM_UART angepasst.
Dabei wird automatisch alles Nötige für den Anwender erzeugt:
- Hardware-Definition in HDL (VHDL) für die Synthese oder Simulation
- Header mit Register-Definitionen für den C-Programmierer
- Register-Referenzdokumentation (Register-Bits, usw.)
Im Rahmen einer Machbarkeitsstudie wurde eine gegenüber der originalen ZPU-Architektur verbesserte schnellere Variante ZPUng mit dreistufiger Pipeline entwickelt, die unwesentlich mehr Logik benötigt und dank einem passenden Befehlsinterpreter vollständig Opcode-kompatibel zum Original ist.
Highlights
- Ethernet und Netzwerk-Stack für Echtzeit-Steuerung per UDP
- Schnelles Daten-Streaming per DMA
- Multitasking-Option
- Auslagerung von Code (Overlay) per SPICache
- Einfaches Update per Netzwerk
Referenzanwendungen
- netpp node: Evalkit für IoT on FPGA
- LED-Array Steuerungen
- MJPEG Streamer Kamera-Referenzdesign mit Hardware-JPEG-Encoder
Alle Anwendungen benötigen weniger als 32kB on-Chip SRAM und normalerweise kein externes Memory.
Ein weiteres Feature ist die Fähigkeit der kompletten Simulation des Programmcode. Werden z.B. Variablen oder Register nicht korrekt initialisiert, tritt dies sofort in der Simulation zutage. Somit lassen sich komplette Programme, sofern sie deterministisch ablaufen, zusammen mit der Hardware und entsprechend virtuellen Stimulationen durchsimulieren und regress-testen.
So sind auch sicherheitsrelevante Funktionen wie hardwaremässige Not-Abschaltung bei fehlerhaftem Verhalten gut verifizierbar.
Für die Simulation wird ‘ghdl’ verwendet, welches quelloffen ist und eine hohe Robustheit aufweist. Insofern ist die vorgestellte Lösung komplett herstellerunabhängig und läuft je nach Konfiguration auf
Plattformen unterschiedlicher FPGA-Hersteller.
Das ‘MaSoCist’-Build-System ist unter einer OpenSource-Lizenz und als Docker container (keine Installation von weiteren Paketen nötig) verfügbar. Gleichzeitig werden Entwickler bei Neuentwicklung ihrer
Komponenten nicht zur Offenlegung ihrer Designs gezwungen.
Weitergehende Informationen (englisch):
https://section5.ch/index.php/documentation/masocist-soc/
Die Links zu Git-Repositories werden hier in Kürze veröffentlicht. Bitte um etwas Geduld.