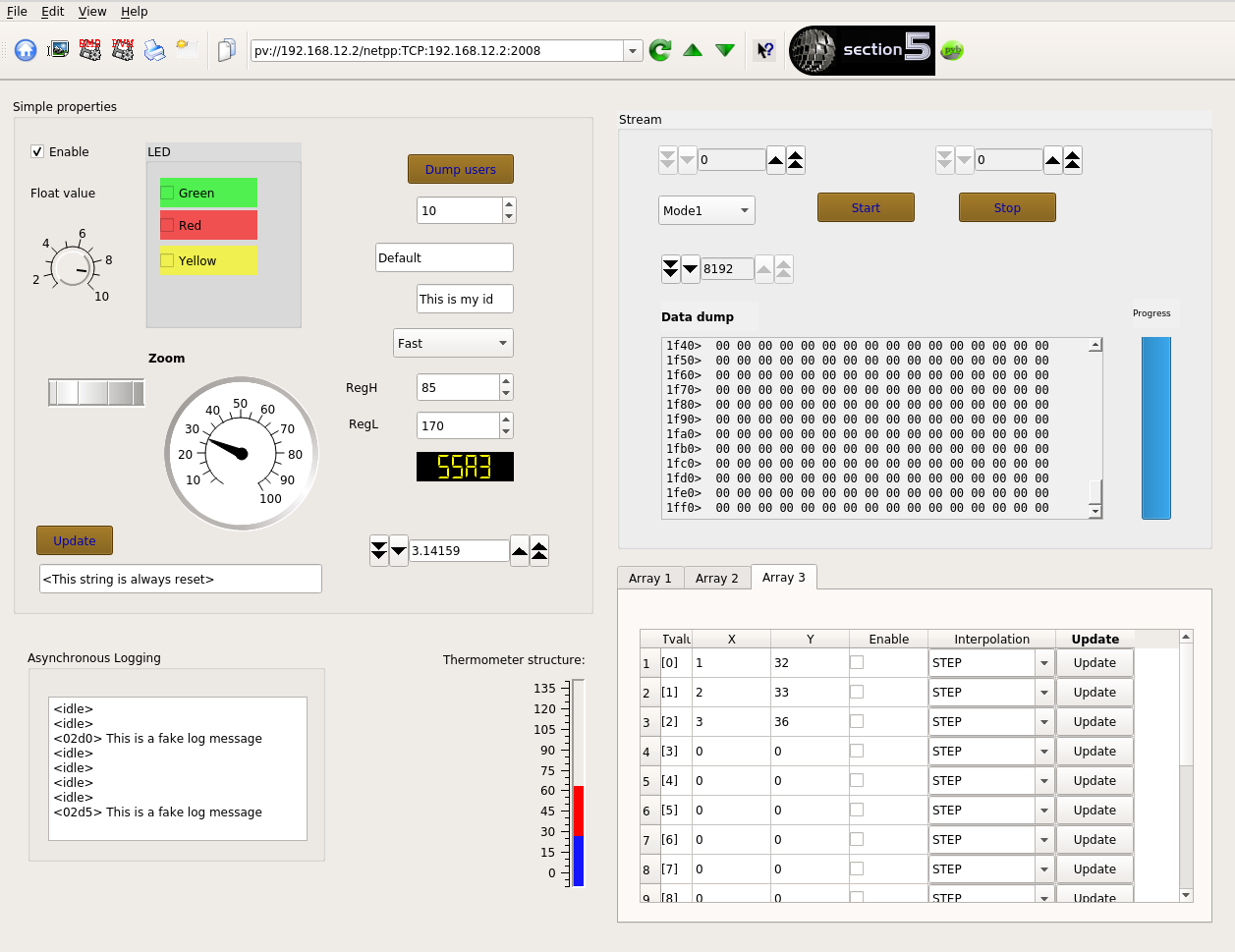
Die Erstellung einer klassischen Prozessansicht in der Automation sieht im Arbeitsprozess aus, wie folgt:
- Registertabellen aus der modbus-Sektion abtippen und mit einer Widget-ID der HMI-Anzeige verbinden
- Zustand eines Elements, z.B. Ventil innerhalb der Prozesskette in verschiedene Bitmaps codieren, z.B.:
- 0 : Initialisierung des Ventils (Zustand unbekannt)
- 1: Ventil offen
- 2: Ventil zu
- 3: Fehler
- In der Abfrage wird laufend der Zustandswert aus dem Register ausgelesen und die entsprechende Bitmap an der Stelle der Prozessübersicht gezeichnet.
Mit dem weitverbreiteten und gut standardisierten Vektorformat SVG geht das eleganter:
- Einem Element in der Grafik einen Namen geben
- Dem Namen über eine Datenbank allenfalls eine Registeradresse zuweisen
- Die ganze Prozedur der Aktualisierung einem Framework überlassen
Diverse SCADA-Lösungen setzen teils auf Browser-Technologien auf, da sie von Haus aus Unterstützung für das SVG-Format mitbringen. Diese benötigen typischerweise einen embedded Webserver, der die regelmässige Abholung der Registerdaten in der ganzen Prozesskette organisiert und für den Browser entsprechend der bereitstehenden REST-APIs aufbereitet. Es gibt aber auch kompaktere Lösungen, die Support für SVG mitbringen, wie die OpenSource-Lösung pvbrowser von Rainer Lehrig.
Hier wird insbesondere die Integration in den pvhub-Prozesskontrolle-Server mit dem netpp-Subsystem beschrieben. Dabei arbeitet man allerdings in der anderen Richtung, d.h. die Netpp-Property-Namen dienen als Namen (‘id’) für das zugeordnete SVG-Element und die zentrale Datenbank fällt weg.
Anleitung
Am Beispiel eines Zwei-Wege-Verteilers soll hier eine kurze Anleitung gegeben werden, wie der Zustand eines Elements elegant in die Grafik überführt wird. Dazu benutzen wir das mächtige Opensource-Tool Inkscape, siehe auch Download. Der Zustand des ZWV ist in einem Register-Bitfeld codiert, welches durch ein netpp-Property vom Typ MODE beschrieben wird. Dieses MODE-Property enthält die möglichen Zustände als Kinder, z.B:
Type : Mode [RWV] Child: (m) [200000d5] 'LR_PUR' Child: (m) [200000d6] 'L_PUR' Child: (m) [200000d7] 'R_PUR' Child: (m) [200000d8] 'OFF' Child: (m) [200000d9] 'LR_ALARM' Child: (m) [200000da] 'L_ON' Child: (m) [200000db] 'R_ON' Child: (m) [200000dc] 'L_ERR' Child: (m) [200000dd] 'R_ERR'
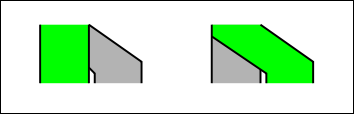
Zeichnen Sie dabei für jeden Zustand eine einzelne Grafik. Arbeiten Sie dabei am besten mit Hilfe von Layern, dass die einzelnen Grafiken direkt übereinander zu liegen kommen. Das erspart nachträgliche und aufwendigere Translationen.
Gruppieren Sie anschliessend jede Grafik per Zustand einzeln. Danach teilen Sie dieser Gruppe einen eindeutigen Namen zu, und zwar den vollen hierarchischen Namen des netpp-Property-Zustands, z.B.
Monitor.ProcessingUnit.Crumbler[0].TwoWayDistState.L_ON
Benutzen Sie dazu allenfalls den XML-Editor in Inkscape:
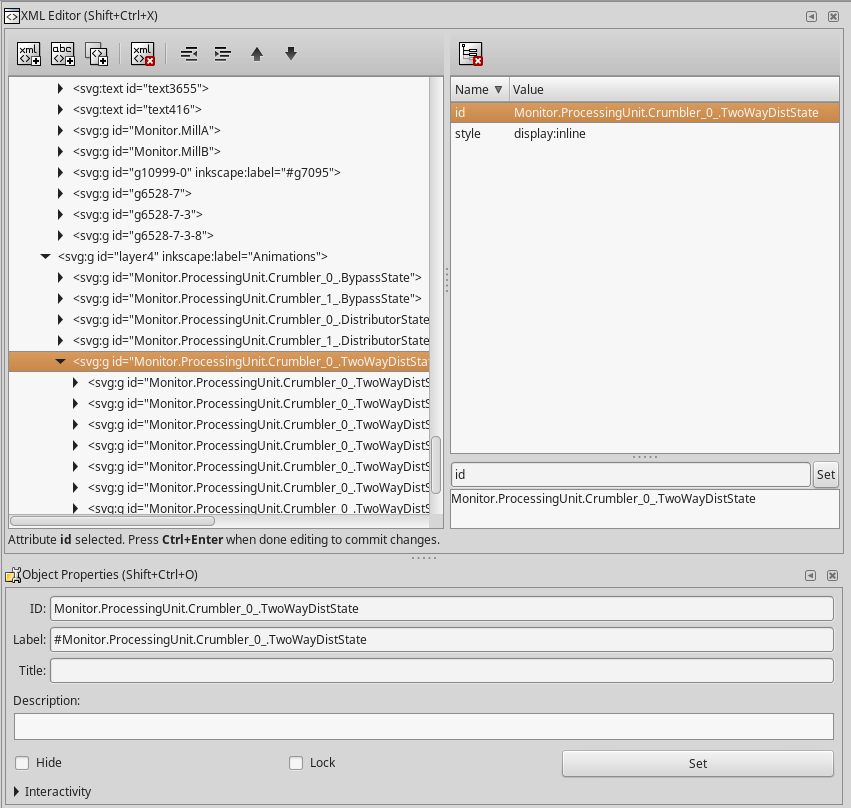
Die Einzelgrafiken werden schlussendlich in einen Layer aufeinander kopiert. Schliesslich müssen alle Zustandsgrafiken noch ein letztes Mal mit Ctrl-G gruppiert werden, dieser Gruppe weisen Sie dann den Namen des Property zu:
Monitor.ProcessingUnit.Crumbler[0].TwoWayDistState
Für eine einfache Umsetzung reicht zunächst, die SVG-Grafik mit dem Rapid-Prototying-Tool pvdevelop (Teil der pvbrowser-Software) einzubinden und ihm die Objekt-ID der gesammelten Monitor-Hierarchie zu übergeben, also: “_#Monitor”. Die Prefix ‘_’ sorgt für die Property-Abfrage, das ‘#’ markiert ein Property das im lokalen Cache gepuffert wird (was eine ineffiziente Abfrage vieler Einzel-Properties optimiert).
Der Ablauf der Prozessanzeige sieht dann aus wie folgt:
- Das Monitor-Property wird einmal pro Intervall abgefragt
- Alle Kinder davon werden “besucht” und deren Zustand ermittelt, der Name des Zustands wird dann verwendet, um das entsprechende Objekt in der Grafik sichtbar zu machen. Dabei werden a priori alle Zustandsgrafiken unsichtbar gemacht und nur die Grafik zum aktiven Zustand wird sichtbar.
Für andere Arten von Eigenschaften nimmt das Framework eine Standard-Anzeige vor, diese ist auch insbesondere vom zugewiesenen Namen des Property abhängig. Dabei werden normalerweise einfache Primitiven (Polygone oder Kreise, etc.) in der Zeichnung verwendet, deren Füllfarbe einfach ausgetauscht wird. Im folgendenden eine kurze Auflistung:
- BOOL: Wert True (1) wird durch grüne Füllfarbe markiert, 0 mit rot
- INT:
- Name: Rotation, Wert von 0..359: Grafik wird entsprechend rotiert
- Name: Position, enthält Min und Max Kinder: Grafik wird um den Wert in X verschoben. Die effektive Positionierung errechnet sich dabei aus der Skalierung des Parent-Property-Objekts. Falls keine Kinder angegeben sind, ist der Wert eine Prozentangabe von 0..100.
- Name: Fill, von 0..100, sofern keine Min oder Max Kinder angegeben, definiert den Füllstand eines Tanks. Die Grafik des Tanks muss dabei die entsprechenden Dimensionen einhalten, die Skalierung findet via das übergeordnete Gruppierungselement statt.
Fazit
Für den Integrator wird die Erstellung einer HMI-Anzeige somit weniger aufwendig, vorausgesetzt die Datenbank der einzelnen Geräte steht bereits oder ist durch bereits netpp-fähige Geräte abgedeckt.
Sie können somit die Grafik und die nötigen Animationen selbst erstellen, und anhand der vorliegenden Property-Referenz einzeln zuweisen. Allfällige Anpassungen der SVG-Grafik sind dabei meist unproblematisch.
Schliesslich können Sie die Anzeige wie gewohnt per pvbrowser aufrufen und sehen entsprechend die Zustände der Elemente in der so animierten SVG-Grafik.
Ein weiterer Vorteil: Die SVG-Grafik benötigt gegenüber der Pixelgrafik weniger Speicherplatz. Somit kann es auch auf limitierten netpp-Geräten im SPI-Flash untergebracht und per Property Monitor.SVGImage abgefragt werden.
Stolperfallen/Tips
Bei der Erstellung der SVG-Grafiken gilt es, einiges zu beachten:
- Zeichnen Sie die Elemente am besten von Anfang an masstabsgetreu, d.h. nutzen Sie mm als Einheit. Typischerweise werden die HMI-Anzeigen so abgestimmt, dass das Element in der richtigen Grösse gezeichnet wird
- Gruppieren Sie erst am Schluss, bevor Sie den Namen zuweisen. Bei Gruppierungsaktionen können Namen verlorengehen.
- Nutzen Sie auch den Objects-Editor (Menü: Object->Objects) zur Kontrolle der Hierarchien und Sichtbarkeit.
- Sie können zusätzlich zur ID auch ein ‘Label’ vergeben, was denselben Namen haben kann, aber nicht eindeutig vorkommen muss. Das erleichtert das Auffinden im Objects-Editor.
- Achten Sie darauf, dass bei rotierenden Animationen der Nullpunkt des Objekts als Rotationszentrum gilt. Die Position kann dann durch eine übergeordnete Gruppe definiert werden. Kennzeichnen Sie ansonsten den Rotationsmittelpunkt durch ein Kreuz, o.ä.