For high speed DMA throughput where you’d want the least interruptions, several CPU cores on the higher end deploy scatter-gather style DMA engines to avoid slow memory copying. Let me give an example:
- Assume you would want to compose a network package and stream it out to a media access controller IP core (MAC)
- You have one Ethernet/IP/UDP/RTP header or alike and you are not planning to change it much during a streaming session
- Your payload might be in memory, but also coming from an external data port (such as a video data)
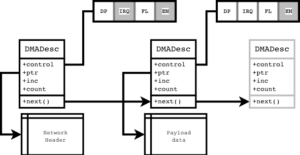
The DMAA core (part of the cCAP families starting with ‘d’, like dombert) allows to set up descriptors in a special shared (and fast) dual port memory such that the DMAA engine can stream almost continuously to a peripheral. Likewise, descriptors can be set up for input streams (peripheral to memory), if required. The above image should talk. You start the DMA engine by writing the descriptor address into the DMAA_START_DESC register. Once the transaction has completed, an IRQ will be fired (which will for example allow you to update the sequence number of an RTP packet). Meanwhile, the DMAA engine will fetch the NEXT descriptor pointer (next()) and stream the payload data pointed to by ptr. You just have to make sure the IRQ routine does not waste too much time doing other things, if you use the same header in the following packet.
Note the control bits: an IRQ will for example only be fired, when the according IRQ bit is set. The EN bit tells the DMA engine to keep going after the current descriptor. The entire transaction stops when the last descriptor has the EN bit set to 0.
In the example for a MAC controller, you might want to append several chunks of data before actually issuing an Ethernet packet. How would the MAC know how long the packet actually is, without explicit (and timing critical) writing of length registers? This is taken care of by the FL (FLUSH) bit. Once a DMA transaction has completed and the FL bit is set, the packet is flushed in one go to the MAC and sent out immediately. The DMA engine waits until the data has been transmitted to the Packet FIFO and then resumes with the next descriptor.
In fact, this concept requires very little logic overhead and can run at high speeds even on small FPGAs (with a reasonable amount of memory buffers shared between DMAA and CPU core)
High speed streaming
When streaming high speed raw data, you might not want the CPU composing packets from external sources. Better stream them directly from the peripheral to the MAC the interleaved way. For the above Payload packet descriptor, the alternative data input method would be by setting the DP (DATAPORT) bit. In this case, the ptr and inc attribute of the descriptor are ignored and `count` number of bytes plus one are taken from the dataport input FIFO. If there is a premature end to the data, a CANCEL action can occur. The DMA will then stop (ignore the EN bit) and the user space program can react accordingly by checking if the DMAA engine is active. The effectively written number of bytes can be read from a DMA_CURCOUNT register and if necessary, padding action can occur.
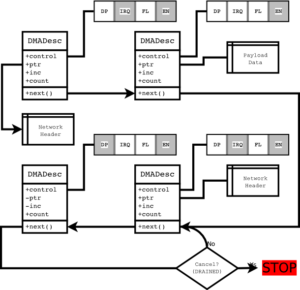
Likewise, receiving packets of a priori unknown sizes is possible using this approach. A receive DMA IRQ handler just checks this register and fills in the effective packet size in the receiver packet queue which is later polled by ‘user space’ (this being the bare metal main loop, typically).
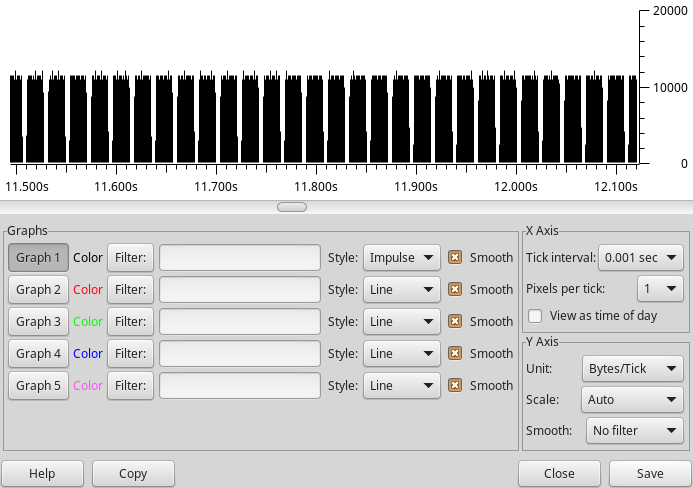
This way, data rates up to the theoretical maximum can be achieved. The rest is a matter of configuring the right packet and FIFO sizes. Below you can see a Wireshark packet graph for a regular packet burst (30 frames per second). As you can see, it’s cranked up to the maximum possible throughput during the burst.
Summary
Advanced DMA capabilities are easy to implement in FPGA SoCs and make high speed transfers possible even with simple and slow CPUs.
Some reference applications:
- Almost-Zero latency streaming of compressed Video over RTP (RealTimeProtocol)
- Signal Analyzer and trace units (‘digital scopes’)