We have been “discovered” by a very aggressive spammer company from Shenzhen area China, claiming to produce PCBs professionally. Despite several friendly warnings, the spam frequency of these emails has increased up to 12 hours before effective blocking.
Therefore all the following addresses have been definitely spam blocked:
*@163.com
*@jsdpcb.com
*@jsd-pcb.com
*.cn addresses, likewise
We recommend to not engage in any business with this company, as their services were evaluated as of no value and their staff turns out to be unprofessional or non-responsive at all.
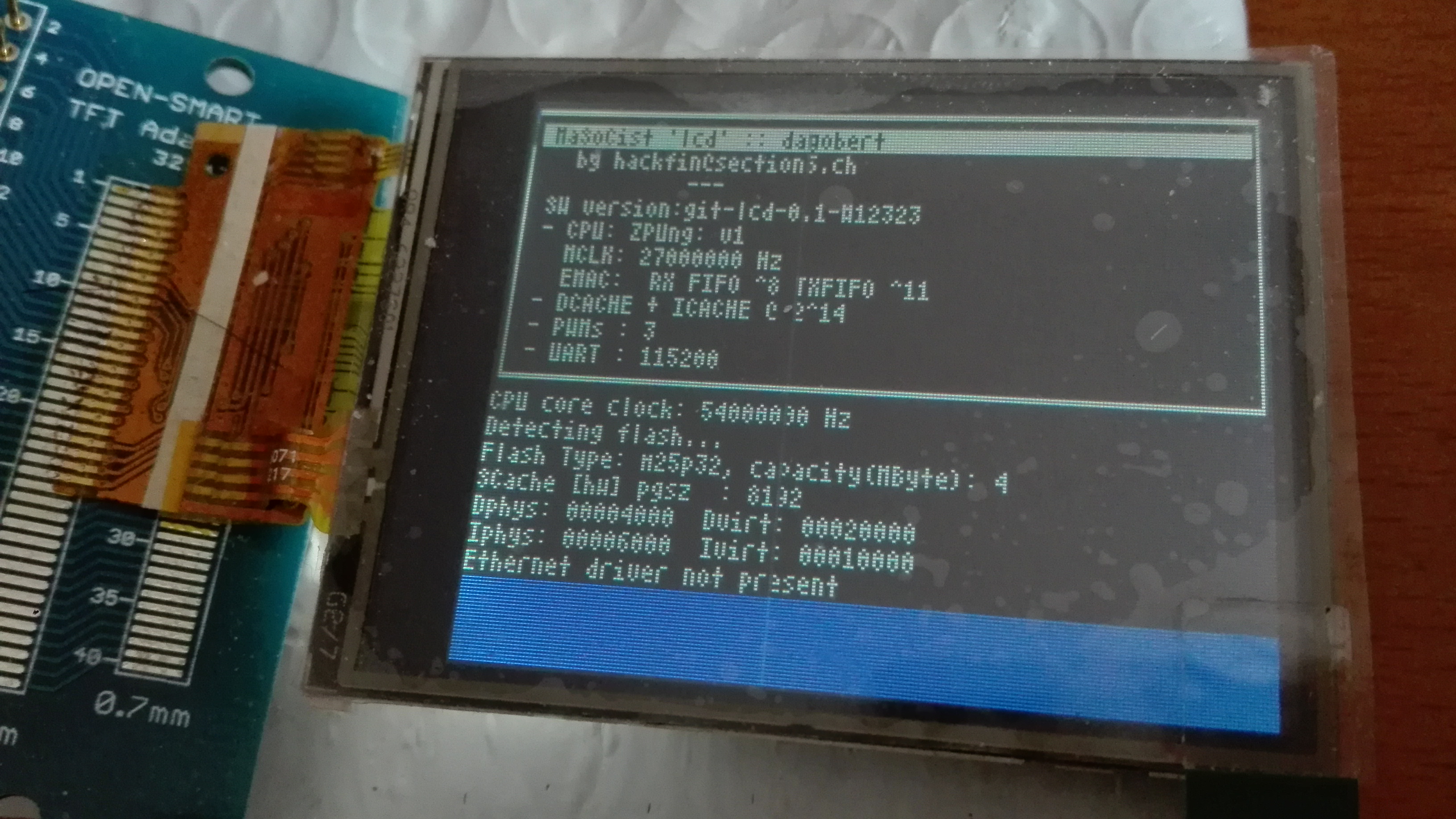
Just as proof of concept, I up-ported the LCD-interface from the ‘beatrix’ SoC to the ‘dagobert’ netpp node default SoC configuration. This also introduces GPIO multiplexing options on port A, meaning, that a few pins have dedicated funcionality driven by an asynchronous bus engine with some extra decompression logic, tailored specifically for LCD screens. Since direct GPIO bit banging would burn a few more cycles and be slow, having a special interface definitely pays off (apart from DMA features, etc.)
The display controller of this OpenSmart variant has different addressing modes, so you can switch between landscape and portrait. However, there’s a catch: When trying to make use of the built-in scrolling feature, it turns out it is only supported for portrait mode, i.e. the shown landscape orientation would require to buffer the terminal content and redraw for each new line.
I have also tried to run a simple GUI toolkit as Achim Döblers µGUI. Due to its simple pixel-wise drawing API it is not very fast, but works ok for most purposes.
What is left to do is the touch screen implementation. This will only work on the ADC10 variant of the netpp node with populated msp430g2553. For now, touch screen is not required, so this task is not scheduled (no pun intended).
Other than that, the same techniques as mentioned in this post are used to save RAM resources using the SCACHE peripheral.
You might save this script to a file like run.sh and start it next time from the Docker Quickstart terminal:
. run.sh
Depending on the MaSoCist release you’ve got, there are different install methods:
Opensource github
See README.md for most up to date build notes. GTKwave is not installed by default. Run
sudo apt-get update gtkwave
to install it.
When you have X support enabled, you can, after building a virtual board, run
make -C sim run
from the MaSoCist directory to start the interactive wave display simulation. If the board uses the virtual UART, you can now also connect to /tmp/virtualcom using minicom.
Custom ‘vendor’ license
You should have received a vendor-<YOUR_ORGANIZATION>.pdf for detailed setup notes, see ‘Quick start’ section.
A few more notes
All changes you will make to this docker container are void on exit. If this is not desired, remove the ‘–rm’ option and use the ‘docker ps -a’ and ‘docker start -i <container_id>’ commands to reenter your container. Consult the Docker documentation for details.
Closing the GTKwave window will not stop the simulation!
Ctrl-C on the console stops the simulation, but does not close the wave window
The UART output of the virtual SoC is printed on the console (“Hello!”). Virtual UART input is not supported on this system, but can be implemented using tools supporting virtual COM ports and Windows pipes.
Once you have the Docker container imported, you can alternatively use the Kitematic GUI and apply the above options, in particular: